Syllabus Map
- Study map: Syllabus Study Map
Overview
- Attention lets each token directly read relevant tokens, instead of compressing everything into one fixed vector.
- Transformers stack attention and feed-forward blocks for scalable sequence modelling.
- Core advantages over RNNs: parallel training and better long-range dependency handling.
Scaled Dot-Product Attention
Definition
- Each token is projected into query (), key (), and value () vectors.
- Attention weights are similarity scores between queries and keys.
- is key dimension; scaling by stabilises logits.
- Without scaling, dot products tend to grow with .
- Large-magnitude logits make softmax too peaky, which shrinks gradients and makes optimisation unstable.
- Dividing by keeps logit scale more consistent across model widths.
- Softmax rows sum to 1, so each token computes a weighted sum of value vectors.
Intuition
- 3Blue1Brown-style intuition:
- Query (): what this token is looking for.
- Key (): what this token can offer (a potential answer to queries).
- Value (): the information payload passed forward if the key matches the query.
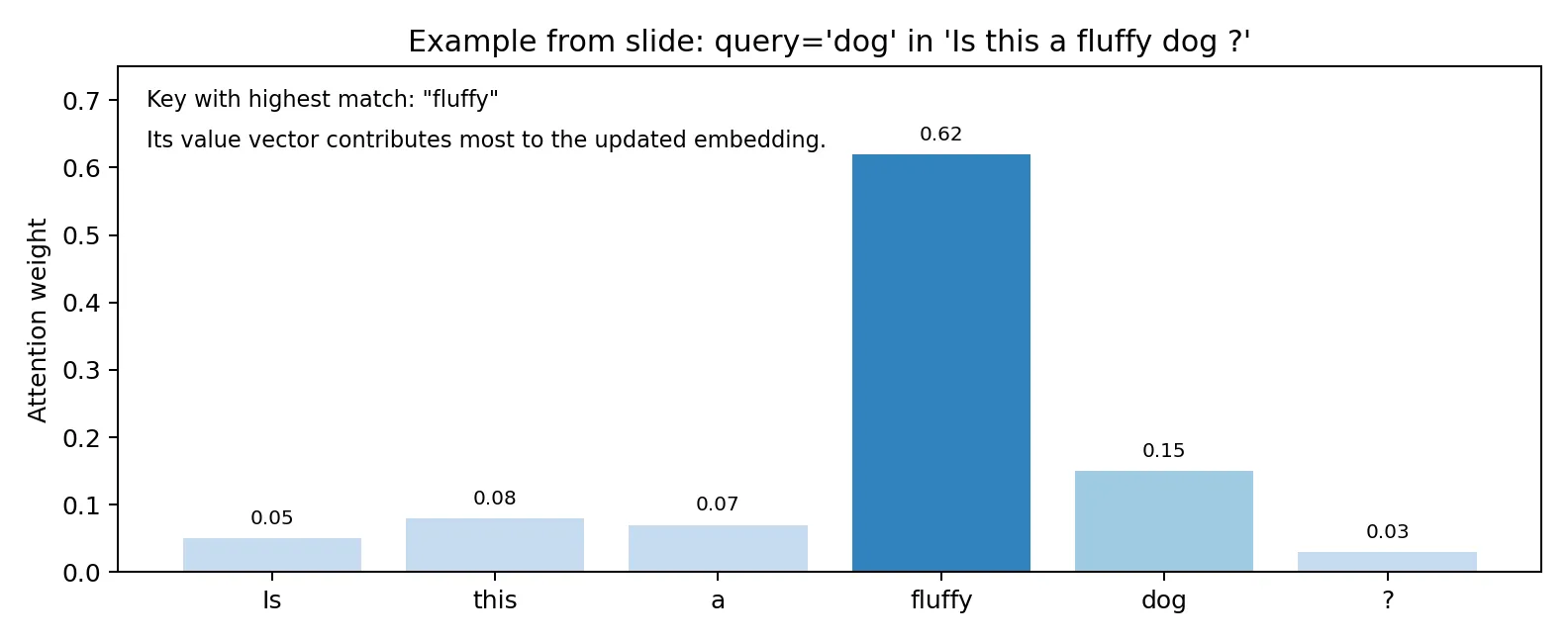
- Example:
- Sentence:
Is this a fluffy dog? - For query token
dog, compare against keys from all tokens. - The word
Fluffygets a high score, so its value vector contributes strongly todog’s updated representation.
- Sentence:
- Each query compares against all keys using dot products.
- Softmax turns scores into weights, then a weighted sum of values builds the context-rich output.
Multi-Head Attention
- Instead of one attention map, use multiple heads to capture different relations.
- is number of heads.
- Different heads often specialise (syntax, positional patterns, long dependencies).
KV-Head Design Variants
Multi-Head Attention (MHA)
- Standard design: each query head has its own key and value projections.
- If a model uses 8 query heads, it also keeps 8 key heads and 8 value heads.
- This is expressive, but KV cache memory grows with the full head count.
- Per head :
- Examples: GPT-3, Llama 1, Phi-1, Phi-2.
Multi-Query Attention (MQA)
- Uses many query heads but shares one key head and one value head across them.
- This greatly reduces KV cache size and speeds decoding.
- Tradeoff: quality can drop slightly compared with full MHA in some settings.
- Shared KV:
- Example: Falcon.
Grouped-Query Attention (GQA)
- Middle ground between MHA and MQA.
- Query heads are split into groups, and each group shares one key/value head pair.
- Reduces memory pressure while usually preserving more quality than MQA.
- For group mapping :
- Examples: Llama 3, Mistral 7B.
Multi-head Latent Attention (MLA)
- Uses a latent-space compression approach for KV representations.
- Designed to further reduce memory and compute cost during decoding.
- One common abstraction:
- Example: DeepSeek-V3.
Transformer Block
- Standard block has:
- Multi-head attention,
- Position-wise feed-forward network (FFN),
- Residual connections and layer normalization.
- FFN is typically two linear layers with nonlinearity (GELU/ReLU).
How FFN Works
- The same FFN is applied independently to each token position.
- Typical form:
- First layer expands dimension (for example ), nonlinearity adds expressive power, second layer projects back.
- Attention mixes information across tokens; FFN then transforms features within each token.
- A common choice is .
Positional Information
- Attention alone is permutation-invariant; position encoding is required.
- Common choices:
- Learned absolute positional embeddings,
- Sinusoidal embeddings,
- Relative/RoPE-style methods in modern LLMs.
Encoder vs Decoder Attention
Encoder Self-Attention
- Bidirectional: token can attend to all tokens in the sequence.
- Used in BERT-like encoders.
Decoder Self-Attention (Causal)
- Masked: token at position can only attend to positions .
- Used in GPT-style autoregressive models.
Cross-Attention
- Decoder queries attend to encoder keys/values.
- Used in seq2seq tasks (translation, summarization).
Complexity and Scaling
- Full self-attention cost is quadratic in sequence length:
- is sequence length and is hidden size.
- Long-context variants (sparse/windowed attention) reduce memory/compute.
Practical Notes
Architecture and Context
- Attention heads and depth matter more than single-layer width for many tasks.
- Longer context improves tasks with long dependencies but raises cost.
Inference Behavior
- Prompt/instruction format strongly affects decoder-model behavior at inference.