RNNs, LSTMs, and GRUs
Syllabus Map
- Study map: Syllabus Study Map
Outline
- Sequence modelling is a machine learning technique for analysing and predicting patterns in ordered data
- This means the sequence (like words in a sentence or stock prices over time) matters
- These sequential models typically consist of:
- RNNs
- LSTMs
- GRUs
RNNs
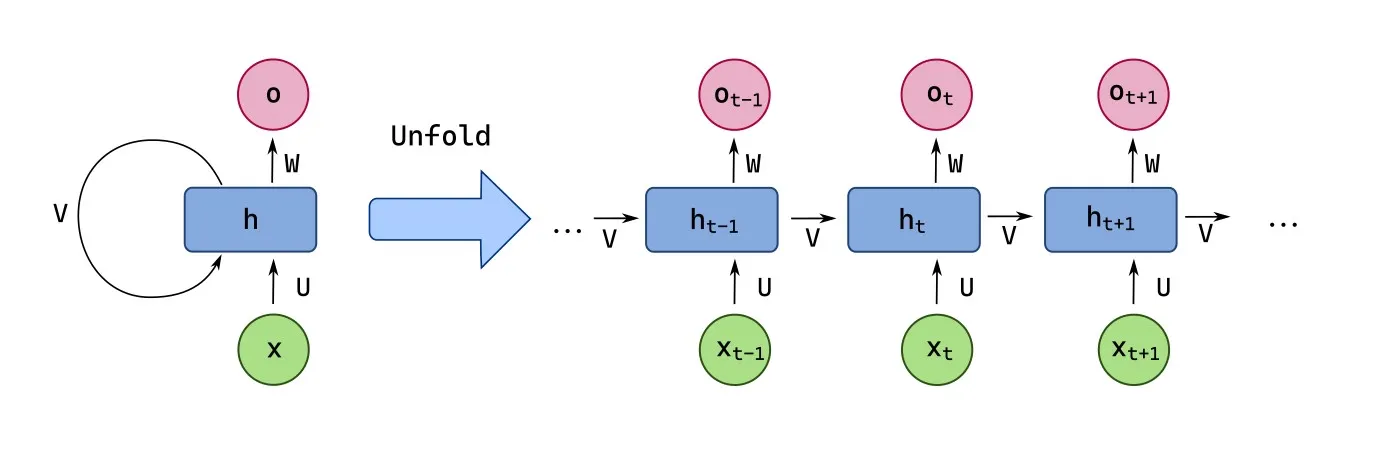
Core idea (high level)
- RNNs process sequences step by step, carrying a hidden state forward
- Each timestep reuses the same weights to incorporate past context
- This simple memory can struggle with long-term dependencies
Notation
- Input at time :
- Hidden state (memory) at time :
- Output at time :
- Previous hidden state:
How it works (specific)
- RNNs utilise recurrent connections, where the output of a neuron at one time step is fed back as input to the network at the next time step
- For a RNN, there are a few things we need to keep track of:
- The current timestep
- The input at the current timestep
- The output at the current timestep
- The hidden states at the previous timestep and current timestep
- Broadly speaking, the RNN can be summarised as a function
1. Set an initial hidden state
- The initial hidden state needs to be passed into the first timestep
- Usually, this is done by setting
- Some implementations learn a trainable instead of using zeros
- The choice of can affect early outputs for short sequences
2. Calculate the hidden state
- Using the hidden state of the previous timestep , take an input to calculate
- The nonlinearity is commonly or
- Weights are shared across all timesteps, which keeps parameter count fixed
3. Calculate the output for this timestep
- Using the hidden state , calculate the output
- The output can be used at every timestep or only at the final step, depending on the task
- A softmax layer is common for classification outputs
4. Pass the current hidden state to the next timestep
- The current hidden state is passed along to the next timestep as a form of input
- Steps 1 to 4 are repeated for all of the sequential data
- Backpropagation through time (BPTT) is used to train the parameters
- Gradients can explode or vanish as sequence length grows
Practical usage
- Short-sequence tasks where long-term memory is not critical (e.g., character-level text, simple sequence classification)
- Baseline time-series forecasting or anomaly detection with limited context
- Lightweight sequence labelling when model size and speed matter
LSTMs
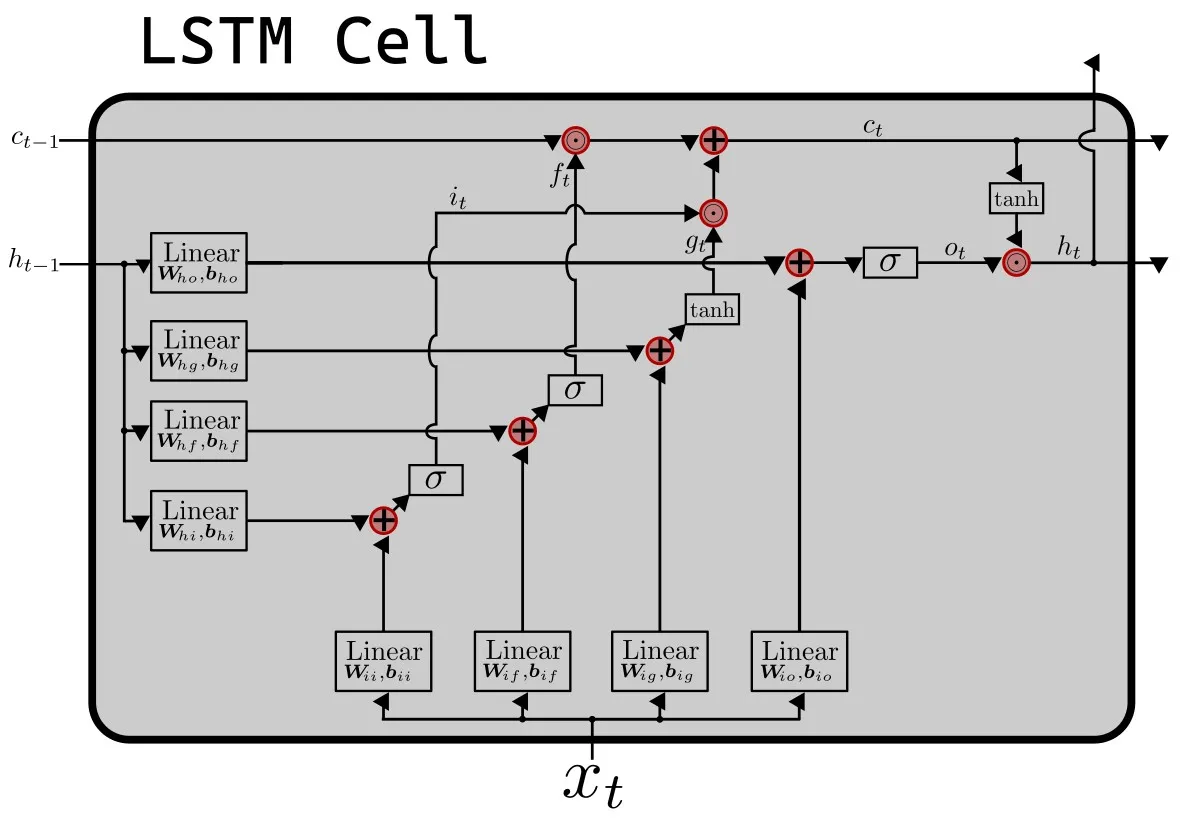
Core idea (high level)
- A standard RNN has one stream of memory that gets overwritten as new inputs arrive
- An LSTM adds a separate, protected memory channel and explicit control mechanisms that decide:
- what to keep,
- what to discard,
- what to output at each time step.
- This gives superiour control over the memory provided to the model at every timestep, splitting the memory into long-term memory and short-term memory
Notation (gates and memory)
- The gates are element-wise values in that control how much information is retained, added, or exposed:
- Forget gate: (how much of to keep)
- Input gate: (how much new information to write)
- Output gate: (how much of the cell state to expose as output)
- Cell state (long-term memory):
- Hidden state (short-term memory/output):
- Input at time :
How it works (specific)
1. Set the initial states and
- Initialise the hidden state and cell state (often zeros).
- Some implementations learn and as trainable parameters
- These initial states seed the memory for the first timestep
2. Compute the forget gate
- The forget gate decides how much of is retained
- Values close to 0 drop old information; values close to 1 keep it
3. Compute the input gate and candidate memory
- The input gate controls how much new information is written to memory
- The candidate memory proposes new content to add
4. Update the cell state
- The cell state blends retained memory with new candidate content
- This pathway helps gradients flow across long sequences
5. Compute the output gate
- The output gate decides how much of the cell state is exposed
- It controls the information sent to the next layer or timestep
6. Compute the hidden state
- The hidden state is the short-term, exposed memory
- It is what downstream layers typically consume
Practical usage
- Long-range dependency tasks (e.g., document classification, language modelling, machine translation)
- Speech recognition and synthesis, where temporal context matters over many steps
- Time-series forecasting with seasonal or delayed effects
GRUs
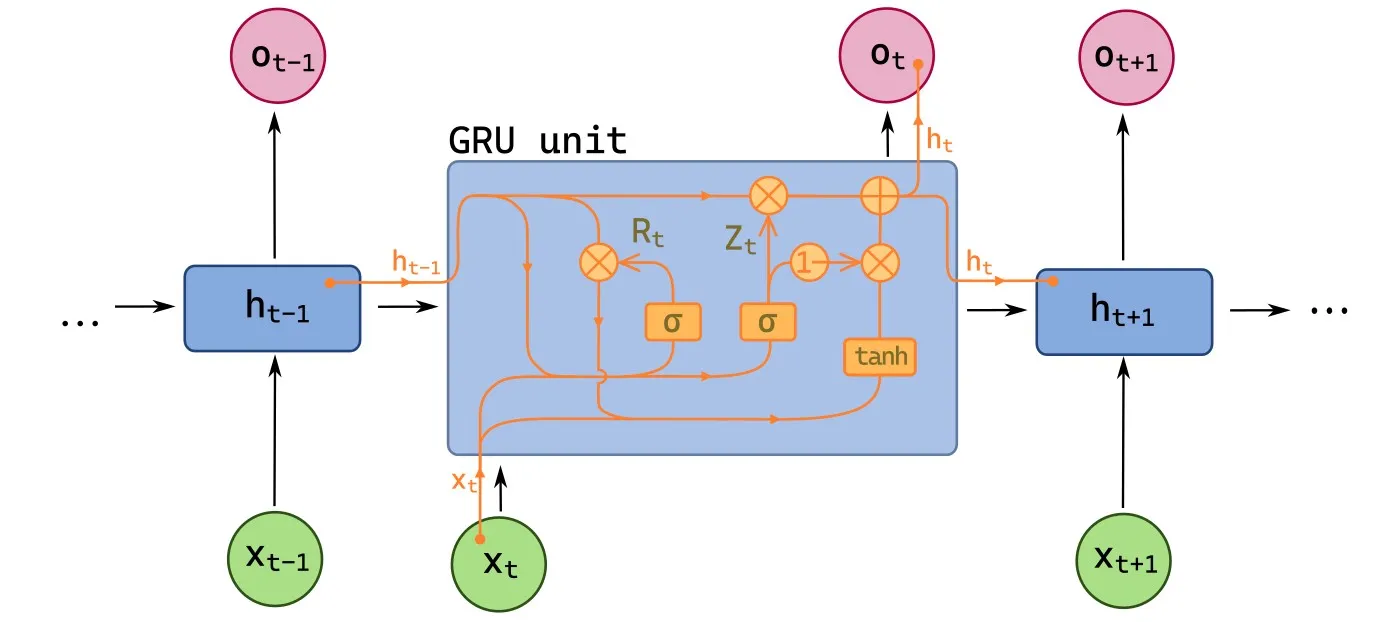
Core idea (high level)
- A GRU merges the LSTM’s cell state and hidden state into a single state
- It uses two gates to control information flow:
- Update gate decides how much past information to keep
- Reset gate decides how much past information to forget when proposing new content
- This makes GRUs simpler and often faster than LSTMs while retaining strong performance
Notation (gates and memory)
- Update gate: (how much of to keep)
- Reset gate: (how much of to use in candidate)
- Hidden state (memory/output):
- Candidate hidden state:
- Input at time :
How it works (specific)
1. Set the initial hidden state
- Initialise the hidden state (often zeros).
- Some implementations learn a trainable
- This state acts as the initial memory before any inputs
2. Compute the update gate
- The update gate controls how much of the past is carried forward
- Larger values preserve
3. Compute the reset gate
- The reset gate controls how much past information influences the candidate
- Smaller values push the model to ignore old context
4. Compute the candidate hidden state
- The candidate mixes current input with a gated version of past state
- It represents the proposed new content for memory
5. Update the hidden state
- The final state interpolates between old and candidate states
- This interpolation is simpler than the LSTM cell/hidden split
Practical usage
- Similar to LSTMs but with fewer parameters, useful for smaller datasets or faster training
- Real-time or edge deployments where model size/latency is constrained
- Robust baselines for many sequence tasks (e.g., sentiment, tagging, forecasting)