Syllabus Map
- Study map: Syllabus Study Map
Overview
- This note covers optimisers, convergence behaviour, and regularisation for neural networks.
- Each section focuses on key ideas, equations, and practical choices that affect training stability and generalisation.
Optimisers
Core idea
- Optimisers update parameters to minimise a loss .
- The basic update is:
- Different optimisers trade off speed, stability, and generalisation.
Gradient descent
- Uses the full dataset to compute the gradient.
- Stable but slow for large datasets.
- Update rule:
SGD
- Uses mini‑batches to approximate the gradient.
- Faster updates, introduces useful noise for generalisation.
- Update rule:
Momentum
- Accumulates a velocity to smooth updates:
- The velocity acts like an exponential moving average of past gradients.
- It builds inertia in consistent directions and filters out noisy updates.
- A typical momentum coefficient is .
- Helps traverse flat regions and damp oscillations.
- Update rule:
Adagrad
- Adapts the learning rate per parameter based on past gradients.
- Good for sparse features, but can decay too aggressively.
- Difference between and :
- is the accumulated sum of squared gradients for each parameter.
- It grows over time, so parameters with large historical gradients get smaller effective steps.
- is the global base learning rate, while is the per‑parameter history that scales it.
- Effective step size is , which shrinks as increases.
- Update rule:
RMSprop
- Fixes Adagrad’s aggressive decay with an exponential moving average.
- Works well for non‑stationary objectives.
- Function of :
- tracks the recent second moment (recent average of squared gradients) for each parameter.
- Large means gradients were recently large, so RMSProp reduces that parameter’s effective step size.
- Small means gradients were recently small, so RMSProp allows a larger effective step size.
- This stabilizes updates and prevents one parameter with large gradients from dominating training.
- Update rule:
Adam
- Combines momentum and RMSprop ideas (first and second moments).
- Strong default for many tasks.
- Update rule:
- is the first moment estimate (EMA of gradients, i.e., mean direction).
- is the second moment estimate (EMA of squared gradients, i.e., gradient magnitude).
AdamW
- Decouples weight decay from the gradient update.
- More reliable regularisation than L2 inside Adam’s adaptive update.
- Common default for transformer‑style models.
- Update rule:
Decoupled weight decay vs L2 in Adam
Adam + L2 (coupled)
AdamW (decoupled)
- Think of weight decay as “gently shrinking” weights every step.
- In classic Adam + L2, the shrink happens inside the adaptive update, so each weight gets shrunk by a different amount.
- In AdamW, the shrink is separate and uniform, so every weight gets the same decay strength.
- This makes AdamW more predictable and usually easier to tune.
Practical Notes
Start with a strong optimizer baseline
- Adam is usually a fast default for early experimentation.
Compare with SGD + momentum for final quality
- On many vision tasks, SGD + momentum remains competitive for generalization.
Tune learning rate before optimizer switching
- Learning-rate choice usually has larger impact than changing optimizer family.
Convergence
What convergence means
- Training loss stabilises and gradients approach zero:
- Validation loss should improve, then plateau without diverging.
Learning rate behaviour
- Too high causes divergence or oscillation.
- Too low causes slow training and poor minima.
- Schedules help balance exploration and refinement:
- Step decay: drop at fixed epochs.
- Cosine decay: smooth reduction over time.
- Warmup: start small, then ramp to target .
Learning rate schedulers
- The learning rate is a hyperparameter that strongly affects convergence.
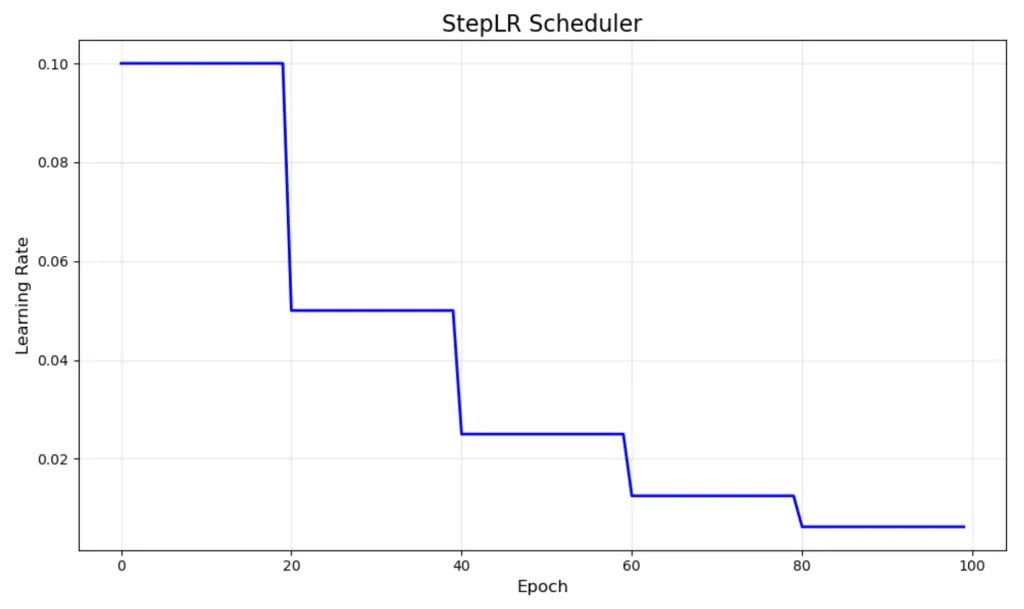
Step-based schedulers
- Drops learning rate by a fixed amount every epochs.
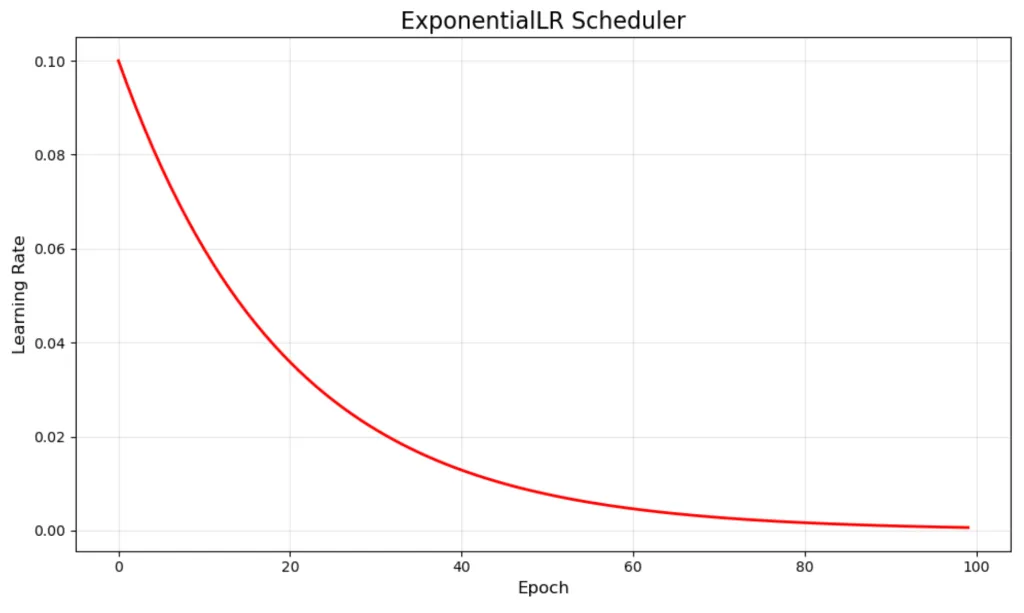
Exponential schedulers
- Smooth exponential decay of learning rate.
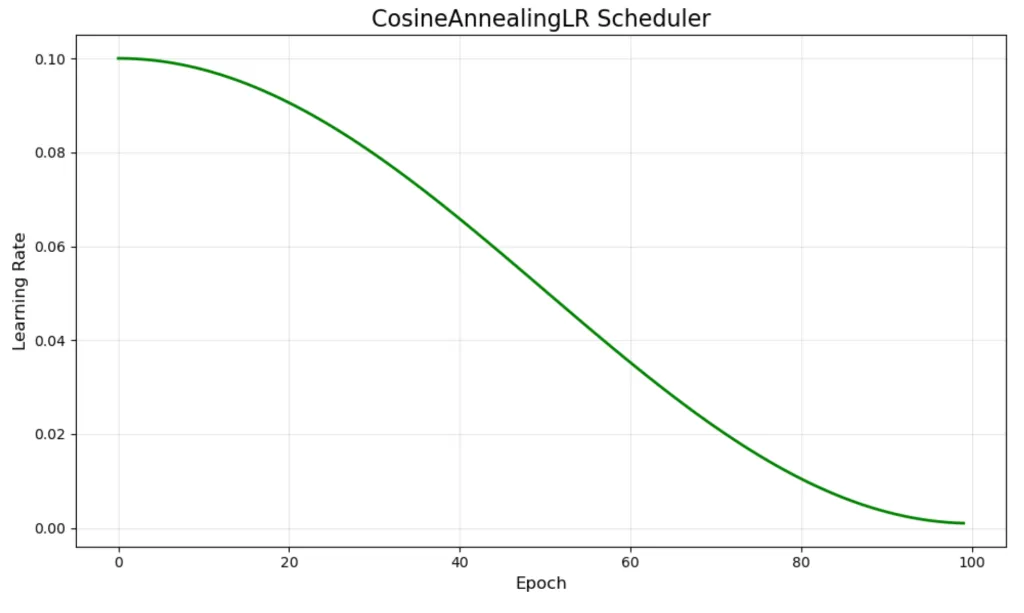
Cosine annealing schedulers
- Smoothly decreases learning rate following a cosine curve.
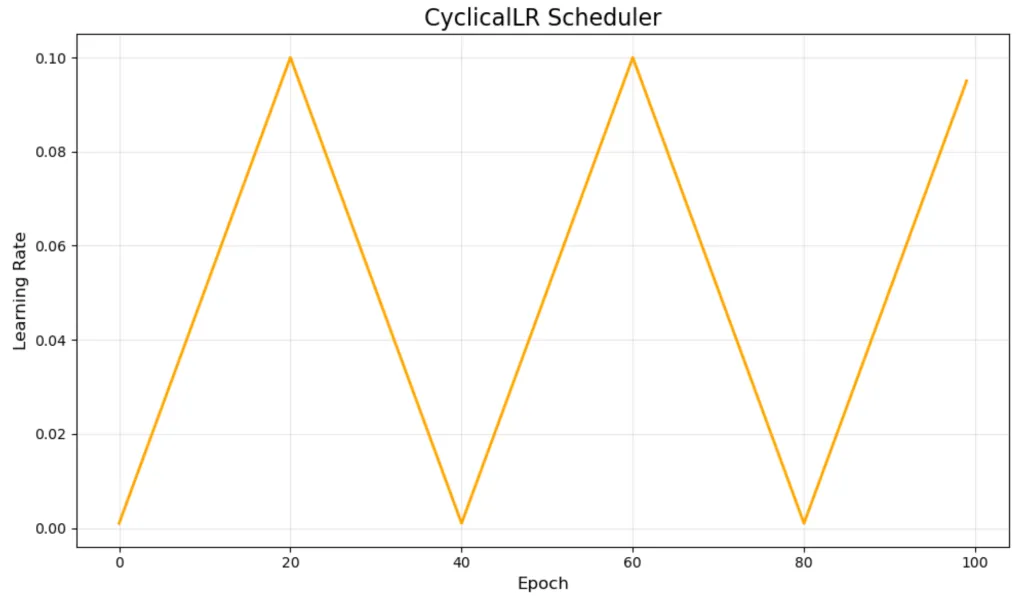
Cyclical schedulers
- Learning rate oscillates between a set of values.
- wtf who designed this
Performance-based schedulers
- Adjust learning rate based on validation performance.
- e.g. ReduceLROnPlateau.
- Adjust LR only when improvement stagnates.
- Adaptive to validation metrics.
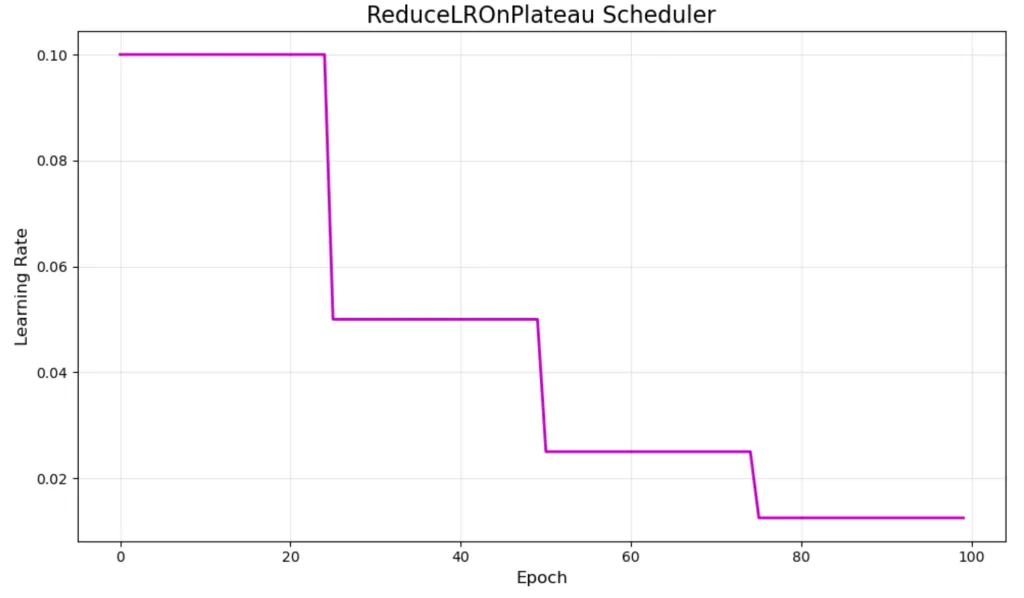
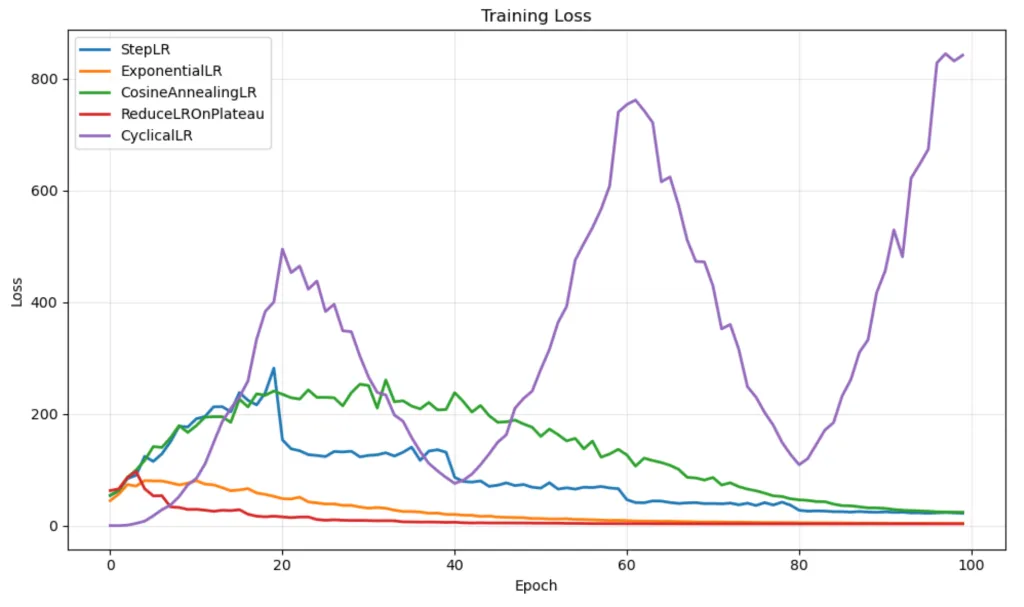
Loss performance on MNIST data
Warmup + decay (typical recipe)
- To stabilise early training, models usually include a warmup phase, starting with a small learning rate and gradually increasing it.
- Once warmup reaches the peak value, gradually decrease the learning rate using the schedulers above.
Diagnostics
- Plot loss curves for train and validation.
- Watch for overfitting (train loss down, val loss up).
- Monitour gradients to detect exploding/vanishing behaviour.
Regularisation
Core idea
- Regularisation adds constraints to reduce overfitting.
- It balances bias/variance by discouraging overly complex solutions.
Dropout
- Randomly zeroes activations during training:
- Forces the network to learn redundant representations.
- Use typical rates: 0.1–0.5 depending on model size.
PyTorch example
import torch.nn as nn
model = nn.Sequential(
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(128, 10),
)Early stopping
- Stop training when validation loss stops improving.
- Saves computation and prevents overfitting.
- Use a patience window (e.g., 5–10 epochs).
PyTorch example
best_val = float("inf")
patience = 5
wait = 0
for epoch in range(100):
# train ...
val_loss = validate(model, val_loader)
if val_loss < best_val:
best_val = val_loss
wait = 0
best_state = {k: v.cpu() for k, v in model.state_dict().items()}
else:
wait += 1
if wait >= patience:
model.load_state_dict(best_state)
breakWeight decay
- Adds L2 penalty to the loss:
- Shrinks weights and improves generalisation.
- Commonly paired with SGD or AdamW.
Label smoothing
- Replaces hard one-hot targets with slightly softened targets.
- Reduces overconfident predictions and can improve generalisation.
- For classes and smoothing factor :
- True class target:
- Each non-true class target:
- Example for , :
- True class target is , others are each.
- Typical values are small (for example
0.05to0.2). - Too much smoothing can hurt class separation and calibration for some tasks.
Practical usage
- Combine data augmentation with regularisation for best results.
- Use dropout more in fully connected layers than in convolutional layers.
- Prefer AdamW when using weight decay with Adam-style optimisers.