Syllabus Map
- Study map: Syllabus Study Map
Overview
- Self-supervised learning builds visual features without manual labels.
- The goal is to learn general representations that transfer to classification, detection, and segmentation.
Core Ideas
Pretext Tasks
- Predict masked patches (masked image modeling).
- Solve contrastive objectives with positive/negative pairs.
- Predict rotations, colorization, jigsaw order (classic but less used now).
Representation Learning
- Learn embeddings that transfer to downstream tasks.
- Evaluate with linear probes, k-NN, or full fine-tuning.
Main Families (Vision)
Contrastive Learning
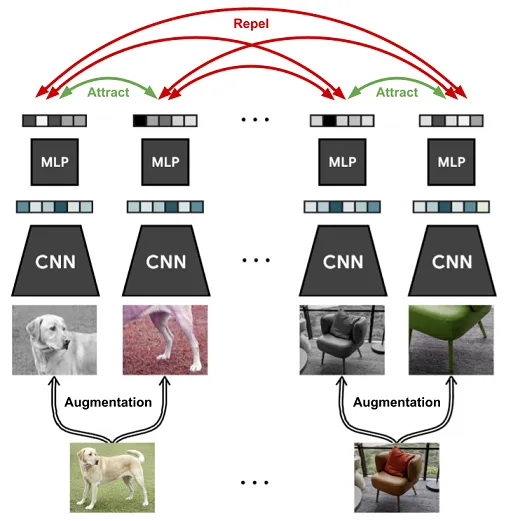
- SimCLR: two augmented views; maximize agreement with InfoNCE loss.
- MoCo: momentum encoder + queue of negatives for scalable contrast.
- SwAV: online clustering with multi-crop augmentation (no explicit negatives).
Bootstrap / Non-Contrastive
- BYOL: online and target networks; stop-gradient avoids collapse.
- SimSiam: predictor head + stop-gradient, no negatives.
Masked Image Modeling
- MAE: mask large portions of patches, reconstruct pixels with a decoder.
- BEiT: predict discrete visual tokens (like a visual vocabulary).
Step-by-Step: Contrastive Learning Objectives
Objective 1: Instance Discrimination (Image-Level)
- Treat each image instance as its own class using two augmented views.
- Pull the positive pair together and push all other images in the batch away.
Objective 2: Image Subsampling / Patching (Patch-Level)
- Split image features into local patches (or crop local regions) and contrast local positives against negatives.
- Positives can be two views of the same patch location/region; negatives are other patches or other images.
Step-by-Step: Instance Discrimination

Step 1: Sample a Batch
- Draw a mini-batch of unlabeled images.
- Larger batches provide more in-batch negatives.
Step 2: Create Two Augmented Views
- Apply two random augmentation pipelines to each image.
- Typical transforms: random crop, color jitter, blur, flip.
Step 3: Encode and Project
- Encode each view with a shared encoder .
- Map encoder features through a projection head to get .
Step 4: Build Positive/Negative Sets
- Positive pair: two views from the same original image.
- Negatives: all other views in the current batch (or memory queue in MoCo).
Step 5: Optimize InfoNCE
- Compute pair similarities and temperature-scaled softmax.
- Backpropagate to update and .
Step 6: Transfer Encoder
- Discard after pretraining.
- Use for linear probing or end-to-end fine-tuning.
Step-by-Step: Image Subsampling / Patching
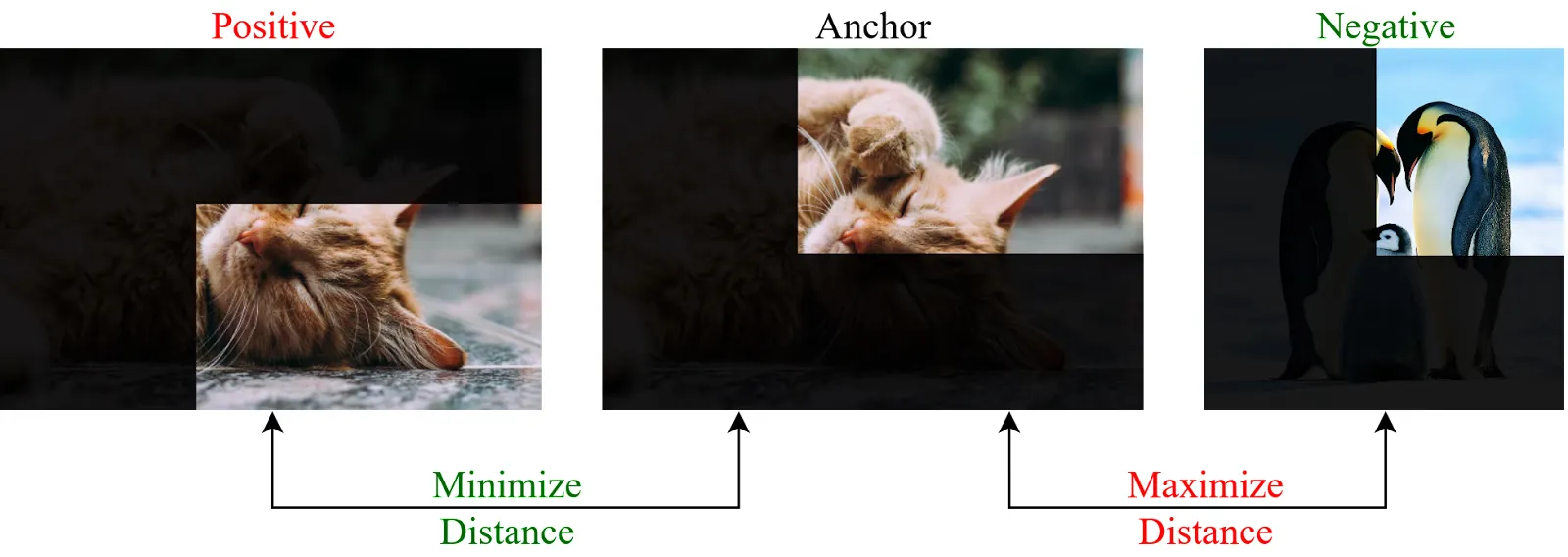
Step 1: Generate Local Regions or Tokens
- Create patches by ViT tokenization or region crops from CNN feature maps.
- Produce two views so corresponding patches can be matched.
Step 2: Encode Local Features
- Extract patch embeddings from both views.
- Optionally add a patch-level projection head.
Step 3: Define Patch Positives and Negatives
- Positive: matched patch/region across two augmented views.
- Negatives: unmatched patches in the same image and patches from other images.
Step 4: Compute Patch Contrastive Loss
- Apply patch-level InfoNCE for each selected patch.
- Average across patches, then combine with image-level loss if used.
Step 5: Update and Transfer
- Optimize encoder and projection heads jointly.
- Keep the encoder for downstream dense tasks (segmentation, detection) or classification.
Key Design Choices
- Augmentations: random crop, color jitter, blur, solarize, and horizontal flip are critical for contrastive methods.
- Backbones: ResNet for early SSL, ViT is now common for MIM.
- Projection head: MLP head often improves representation quality.
- Losses: InfoNCE for contrastive, cosine regression for BYOL/SimSiam, reconstruction loss for MAE.
Practical Notes
Data and Compute
- Requires large, diverse datasets.
- Contrastive methods are compute-heavy due to multiple views per image.
- Masked image modeling scales well with ViT and large datasets.
Evaluation and Transfer
- Often used before supervised fine-tuning.
- Linear probing is the fastest way to compare SSL methods fairly.