Syllabus Map
- Study map: Syllabus Study Map
Overview
- Pre-trained vision encoders turn images into feature vectors or feature maps.
- They provide strong starting weights so you can fine-tune with less data and time.
- Typical workflow: load a backbone, replace the classifier head, then train.
ResNet
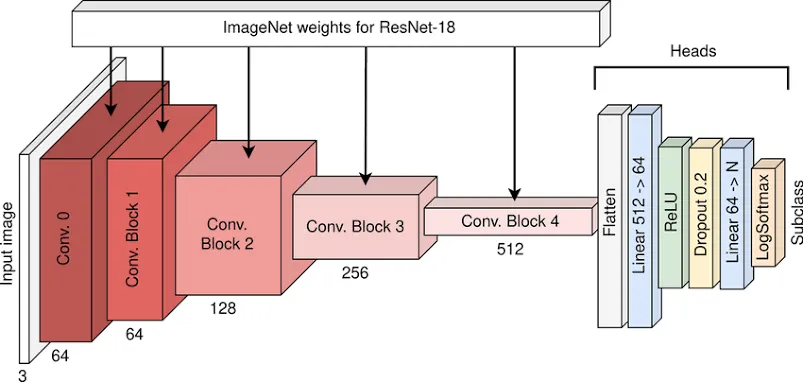
Core idea
- Learn residual mappings so each block refines features rather than relearning them.
- Skip connections keep gradients stable in very deep networks.
How it works
-
Residual block: compute with a few convolutional layers, then add the input.
-
Identity mapping: keeps information flowing.
-
Stage stacking: multiple residual stages progressively downsample and widen channels.
-
What makes it unique: residual skip connections stabilise very deep CNNs.
-
When to use: a reliable default for classification, detection, and segmentation.
PyTorch access
from torchvision import models
model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
model.fc = nn.Linear(model.fc.in_features, num_classes)Pre-activation ResNets
Key difference
- Post-activation:
Conv → BN → ReLU(classic). - Pre-activation:
BN → ReLU → Convinside the block.
Why it helps
- Cleaner identity path for the skip connection.
- Improves gradient flow and optimisation in very deep nets.
Hypothesis Space (Intuition)
- ResNets reparameterise the function space around the identity.
- Easier to search near than arbitrary .
- Can be viewed as an ensemble of shallow paths through the network.
Architecture Comparisons
ResNet vs VGG
- VGG: deeper stacks of convs but no skips → degradation at high depth.
- ResNet: skips stabilise very deep training.
DenseNet vs ResNet
- ResNet: addition of features.
- DenseNet: concatenation of features (feature reuse).
- DenseNet improves gradient flow and feature reuse but uses more memory.
Addition vs concatenation
- Addition: same dimensionality, cheaper memory.
- Concatenation: increases channels, richer features, higher memory cost.
Failure Cases & Tradeoffs
- Very deep nets can still be hard to optimise if data is small.
- Pooling or aggressive stride can remove spatial detail (hurts localisation).
- Residuals help less when the task doesn’t benefit from depth.
- DenseNet: strong accuracy and reuse, but memory-heavy.
Practical Notes
Widely adopted in modern CNN backbones
- Residual connections are a default design in many ResNet-style models.
Improves deep-network optimization stability
- Skip connections help gradient flow with minimal parameter overhead.
VGG
- Use simple, repeated convolutions to build depth.
- Keep architecture uniform to make behaviour predictable.
How it works
-
Conv stacks: several layers per stage.
-
Pooling: downsample after each stage to grow receptive field.
-
Classifier head: large fully-connected layers at the end.
-
What makes it unique: simple stacks of convolutions and large fully-connected heads.
-
When to use: baseline or feature extraction when model simplicity matters.
PyTorch access
from torchvision import models
model = models.vgg16(weights=models.VGG16_Weights.DEFAULT)
model.classifier[-1] = nn.Linear(model.classifier[-1].in_features, num_classes)MobileNet
Core idea
- Factorise standard convolution to reduce compute on mobile hardware.
- Separate spatial filtering from channel mixing.
How it works
- Depthwise conv: one filter per input channel.
- Pointwise conv: conv mixes channels.
- Compute saving:
-
Notation:
- : kernel size (assume square).
- : input height and width.
- : input channels.
- : output channels.
-
What makes it unique: depthwise separable convolutions to cut compute.
-
Compute comparison:
- When to use: mobile and edge devices where latency and size matter.
PyTorch access
from torchvision import models
model = models.mobilenet_v3_small(weights=models.MobileNet_V3_Small_Weights.DEFAULT)
model.classifier[-1] = nn.Linear(model.classifier[-1].in_features, num_classes)EfficientNet
Core idea
- Scale depth, width, and resolution together in a balanced way.
- Use a fixed scaling rule instead of tuning each dimension separately.
How it works
-
Baseline: start from a small model.
-
Compound scaling: increase depth, width, and input resolution with one coefficient.
-
Consistent gains: improves accuracy while controlling FLOPs.
-
What makes it unique: compound scaling of depth, width, and resolution.
-
When to use: strong accuracy-per-parameter and accuracy-per-FLOP trade-offs.
PyTorch access
from torchvision import models
model = models.efficientnet_b0(weights=models.EfficientNet_B0_Weights.DEFAULT)
model.classifier[-1] = nn.Linear(model.classifier[-1].in_features, num_classes)ConvNeXt
Core idea
- Modernise ConvNets using transformer-inspired design choices.
- Keep convolutional inductive bias but update blocks and training recipes.
How it works
-
Large kernel depthwise conv captures broader context.
-
LayerNorm + GELU replaces BN + ReLU for stability.
-
Stage design aligns with modern training regimes.
-
What makes it unique: modernised ConvNet blocks with large kernel depthwise conv, LayerNorm, and GELU.
-
When to use: strong ConvNet baselines that compete with transformers.
PyTorch access
from torchvision import models
model = models.convnext_tiny(weights=models.ConvNeXt_Tiny_Weights.DEFAULT)
model.classifier[-1] = nn.Linear(model.classifier[-1].in_features, num_classes)Vision Transformer (ViT)
Core idea
- Treat image patches as a sequence of tokens.
- Use self-attention to model global relationships across the image.
How it works
-
Patchify: split into patches and flatten.
-
Embed + position: map to tokens and add positional encodings.
-
Transformer: apply multi-head self-attention blocks.
-
What makes it unique: splits images into patch tokens and applies transformer attention.
-
Patch count:
- When to use: large datasets or strong pretraining where attention can shine.
PyTorch access
from torchvision import models
model = models.vit_b_16(weights=models.ViT_B_16_Weights.DEFAULT)
model.heads.head = nn.Linear(model.heads.head.in_features, num_classes)DenseNet
Core idea
- Reuse features by connecting each layer to all later layers.
- Improve gradient flow and parameter efficiency.
How it works
-
Dense block: each layer receives all previous feature maps.
-
Growth rate: control how many new channels each layer adds.
-
Transition layers: compress and downsample between blocks.
-
What makes it unique: dense skip connections reuse features across layers.
-
When to use: parameter-efficient models with strong feature reuse.
PyTorch access
from torchvision import models
model = models.densenet121(weights=models.DenseNet121_Weights.DEFAULT)
model.classifier = nn.Linear(model.classifier.in_features, num_classes)Practical Notes
Use for transfer learning.
- Pretrained encoders usually provide stronger results and faster convergence than training from scratch on small datasets.
Freeze early layers when data is limited.
- Freezing low-level layers reduces overfitting and compute when labeled data is scarce.