Syllabus Map
- Study map: Syllabus Study Map
Overview
- Generative models synthesise realistic images.
- Two major families are GANs and diffusion models.
- GANs are usually faster at sampling; diffusion models are usually more stable and higher quality.
GAN (Generative Adversial Network)
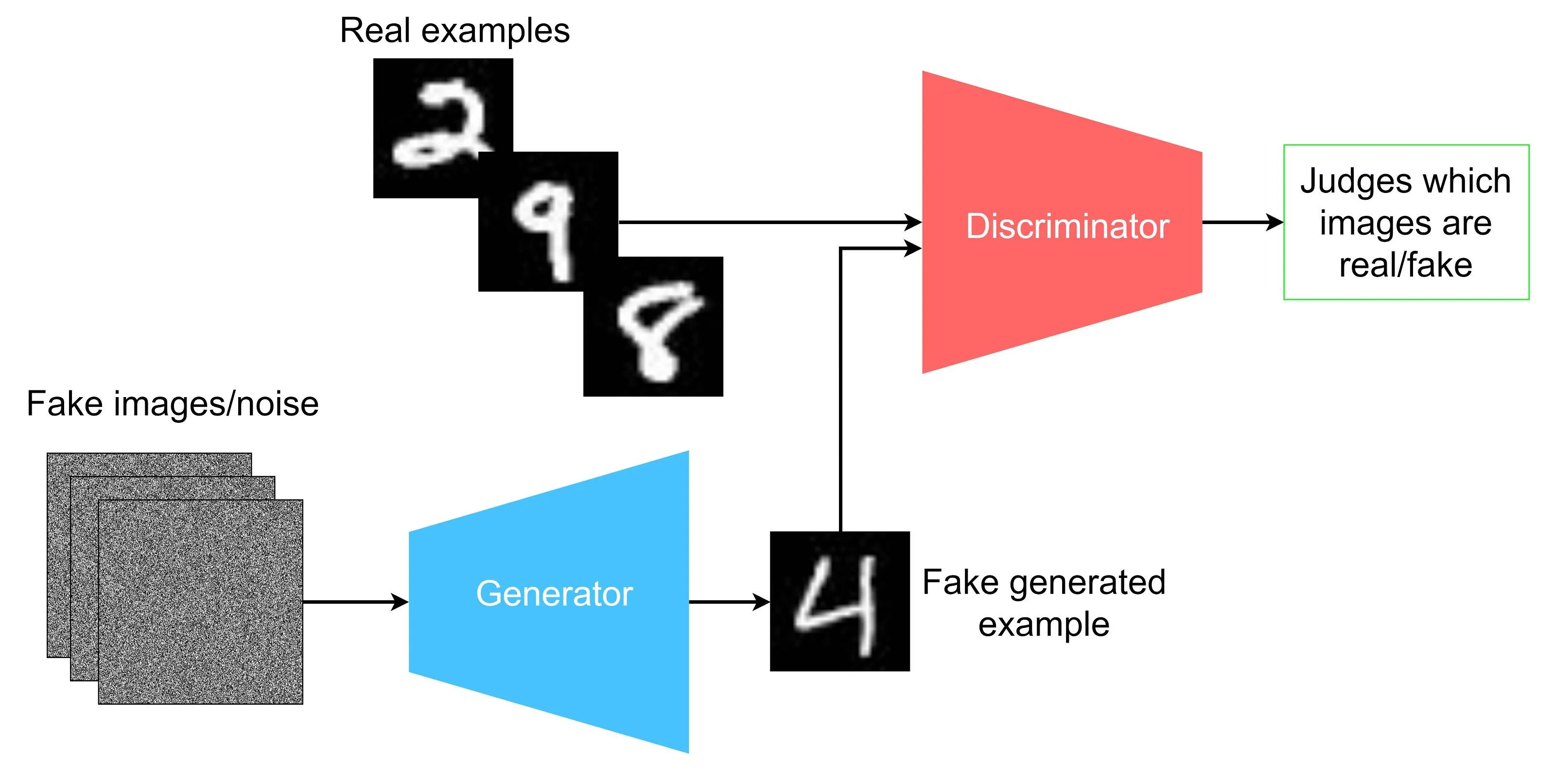
Core Idea
- Generator maps latent noise to an image .
- Discriminator predicts whether an image is real () or generated ().
- Training is adversarial:
- is the real image distribution.
- is latent prior (typically Gaussian).
Step-by-Step GAN Training
Step 1: Sample data and latent vectors
- Draw real images from the dataset.
- Draw noise vectors .
Step 2: Update discriminator
- Train to assign high score to real images and low score to generated images.
- This improves real/fake separation.
Step 3: Update generator
- Train to produce images that fool .
- Generator gradients flow through discriminator feedback.
Step 4: Alternate updates
- Repeat discriminator and generator updates.
- Keep training balanced to avoid one network overpowering the other.
Important GAN Variants
- DCGAN: convolutional baseline for stable image generation.
- WGAN / WGAN-GP: Wasserstein objective + gradient penalty for improved stability.
- StyleGAN2/3: style-based generator with strong photorealism and controllability.
Practical Notes
Training stability is the main challenge
- GAN optimization can oscillate or diverge if updates are not balanced.
Balance generator and discriminator updates
- Keep and learning rates and update frequencies well matched.
Watch for mode collapse
- Generated samples may lose diversity even when quality appears high.
- Mode collapse means the generator finds a small set of outputs that reliably fool the discriminator and keeps repeating that pattern.
- If one “good enough” dog image keeps fooling , may stop learning other dogs and keep producing near-duplicates.
Track quality with standard metrics
- FID and IS are common diagnostics alongside qualitative inspection.
Diffusion Models

Core Idea
Denoising Process
- Learn to denoise from random noise to a data sample.
- Forward process gradually adds Gaussian noise to images.
- Reverse process learns to remove noise step-by-step.
Markov Formulation
- The diffusion process is a Markov chain: each state depends only on the previous state, i.e., .
- Here, is the sample at the previous step, is the noisier sample at step , and is the step- noise variance.
Model Components
- In most modern diffusion models, the denoiser is a U-Net that predicts noise at each timestep.
- In latent diffusion (for example Stable Diffusion), a VAE encodes images into latent space before diffusion and decodes latents back to pixels after denoising.
Text Conditioning
- Text-conditioned models commonly use a CLIP text encoder to convert the prompt into embeddings used to condition the U-Net (typically via cross-attention).
Step-by-Step Diffusion Training
Step 1: Sample image and timestep
- Draw clean image (original data sample) and random timestep .
Step 2: Add noise
- Sample and form noisy sample:
- is sampled Gaussian noise, and is the cumulative signal-retention factor up to step .
Step 3: Predict noise
- Train denoiser to estimate the injected noise.
- is the model’s predicted noise, and is optional conditioning input (for example text prompt).
Step 4: Optimize denoising loss
Step 5: Sample images
- Start from , where is the near-pure noise state at the final diffusion step.
- Iteratively denoise from timestep down to .
Guidance and Samplers
Classifier Guidance (Older Approach)
- Before CFG, diffusion models used an external classifier to guide sampling toward class .
- The reverse update adds a classifier gradient term that pushes samples toward higher class probability.
- This improves condition fidelity but needs a separate noisy-image classifier and can reduce sample diversity.
Classifier-free guidance (CFG)
- During training, randomly drop the condition some fraction of the time so the same model learns both conditioned and unconditioned predictions.
- At inference, run the model twice (conditioned and unconditioned) and combine them with guidance scale .
- denotes unconditioned input, and is guidance scale; larger values strengthen condition fidelity but can reduce diversity.
- Common samplers: DDPM, DDIM, and DPM-Solver variants.
DDIM (Denoising Diffusion Implicit Models)
- DDIM uses a non-Markovian reverse process that can sample with fewer steps than DDPM.
- It can be deterministic (), which makes generation faster and more consistent for the same seed.
- A common DDIM update is:
- Setting (equivalently ) gives deterministic sampling; larger adds stochasticity and diversity.
Inpainting
- Inpainting generates missing or edited regions while preserving unmasked context.
- Provide the original image and a binary mask; the model denoises mainly inside masked areas and keeps known pixels fixed.
- This is useful for object removal, region editing, and prompt-based local modifications.
Practical Notes
Delivers strong image quality
- Diffusion models are often strong on realism and diversity.
Inference is usually slower than GANs
- Multiple denoising steps increase latency compared with one-pass generators.
Latent diffusion improves efficiency
- Denoising in compressed latent space reduces memory and compute cost.
Tune sampler controls carefully
- Noise schedule, denoising steps, guidance scale, and sampler strongly affect output behavior.
GANs vs Diffusion (Quick Comparison)
- Training stability: diffusion usually easier to optimize.
- Sampling speed: GANs are usually faster (single pass).
- Quality/diversity: modern diffusion is usually stronger.
- Conditioning: diffusion integrates text/image guidance naturally.