Syllabus Map
- Study map: Syllabus Study Map
Overview
-
Support Vector Machines (SVMs) are effective out-of-the-box classifiers.
-
SVM is also a generalisation of the maximal margin classifier.
-
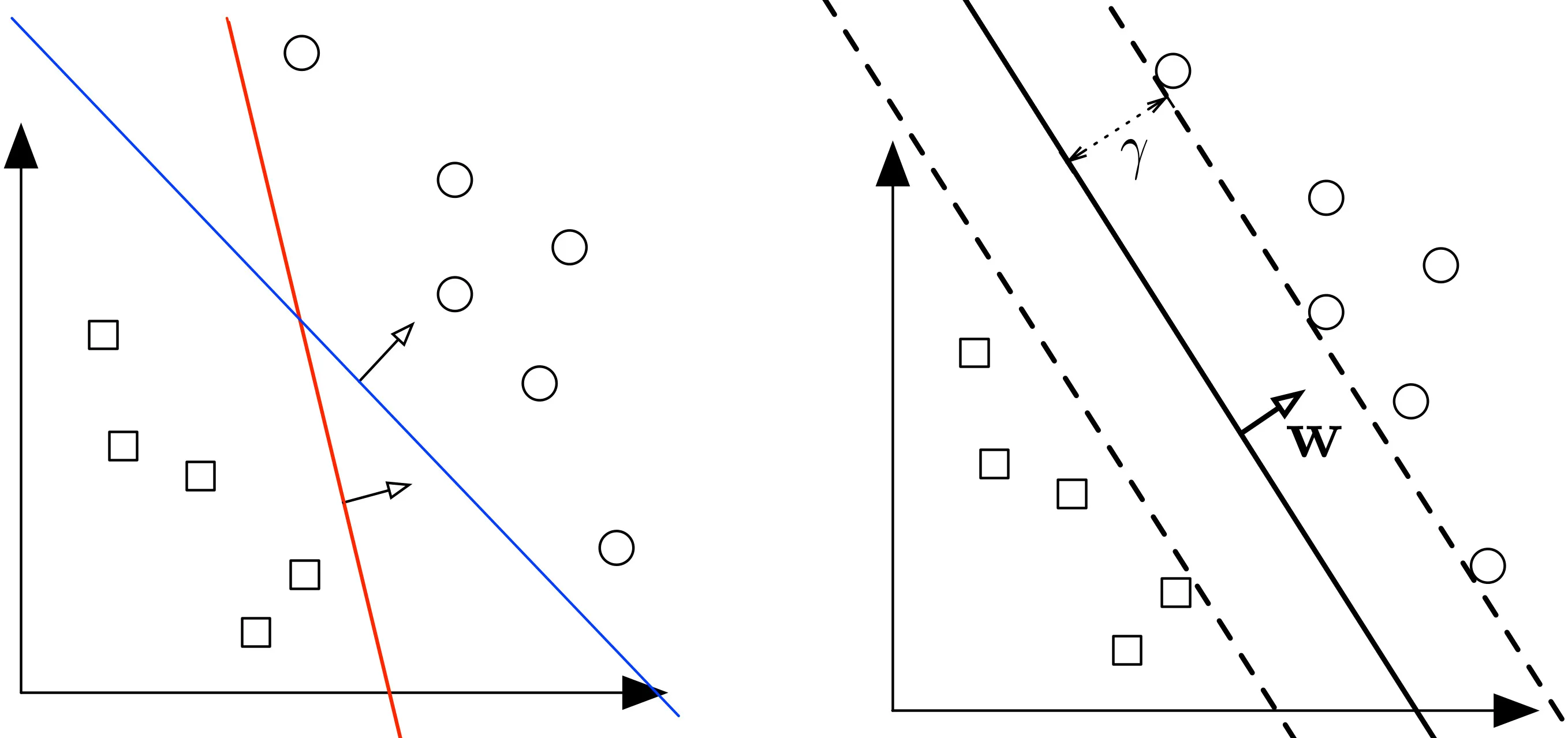
Assuming we have a dataset with two classes, we want to find the optimal hyperplane which can separate the two classes.
-
The margin refers to the minimum distance between two data points of two different classes perpendicular to the direction of the hyperplane.
What is a Hyperplane?
-
For a hyperplane in dimensions, it is defined as a flat affine subspace with dimensions.
-
In other words, a hyperplane can be thought of as a decision boundary.
Defining the separating hyperplane
-
Assume we have a dataset in a two-dimensional space which can be linearly separated, the hyperplane dividing the data points according to their classes is a line.
-
The hyperplane can be defined as the set of points which satisfy the equation:
- If we select two hyperplanes and with the same distance from , and ensuring that each data point lies on the correct side with no data in between, they can be defined as:
- Where:
Finding the optimal separating hyperplane
-
Since our dataset can be perfectly separated using a hyperplane and any hyperplane can be shifted and rotated, there are an infinite number of possible solutions.
-
The optimal separating hyperplane is the solution that is farthest away from the closest data point, or maximises the margin.
Defining the margin
-
In order to maximise the distance between the two hyperplanes, we need to find a way to calculate the margin.
-
The margin can also be interpreted as a direction perpendicular to the hyperplane with a magnitude equal to the margin.
1. Distance from a point to a hyperplane
- For any point , the distance to the hyperplane
is:
2. Distance between the two margin hyperplanes
- The margin hyperplanes are:
- Thus, the distance between two parallel hyperplanes is:
3. Optimiser Function
- Note that we want to maximise the margin hyperplane to form an optimised classification boundary, i.e.:
- Plugging in the definition of the margin:
- Maximising the margin is equivalent to:
- Minimising the denominator
- Minimising the squared norm
4. Primal Optimisation Problem
- Maximising the margin is equivalent to minimising the squared norm of the weight vector.
5. Lagrangian Optimisation
-
We introduce the Lagrangian multipliers for each constraint.
-
In general, for the equality constraint of , the Lagrangian is:
-
Where
- is the Lagrangian,
- is the Lagrangian Multiplier,
- is the function,
- is the equality constraint
-
In this case, the Lagrangian is:
6. Finding Partial Derivatives
-
Now, we optimise this Lagrangian by differentiating with respect to
-
Finding the partial derivative of with respect to :
- Finding the partial derivative of with respect to :
- Finding the partial derivative of with respect to :
7. Support Vectors
- Setting the partial derivative of with respect to to :
- Thus, only points that lie exactly on the margin satisfy:
-
These points are called support vectors.
-
All other points lie strictly outside the margin and do not affect the position of the decision boundary.
8. Decision Rule
- Once and are learned, predictions are made using:
- If , predict class .
- If , predict class .
- Where the distance from boundary measures confidence.
Soft Constraints
-
If the data is low dimensional, it is often the case that there is no separating hyperplane between the two classes.
-
By introducing two terms, we can allow more “slack” in determining a (mostly) optimal margin hyperplane.
-
The new terms are:
- : Slack variable which gives an acceptable margin of Error, allowing input to be closer (or even the wrong side) of the hyperplane.
- : Slack penalty which controls how much slack is allowed.
-
Thus, the constrained optimisation problem becomes:
Bias–Variance Tradeoff via
- controls penalty for misclassification.
- Large : Low bias, High variance (Overfitting risk)
- Small : High bias, Low variance (Underfitting risk)
Acts as a regularisation parameter.
Geometric Interpretation of the SVM
- In vector form,
- is perpendicular (normal) to the hyperplane.
- controls the offset of the hyperplane from the origin.
- controls the margin width.
- Larger → smaller margin.
- Smaller → larger margin.
- Classification is based on the sign of .
- Thus, SVM chooses the boundary that is most robust to perturbations.
Kernel Trick and RBF Kernel
- For nonlinear data, SVM can use a kernel to compute similarity in an implicit higher-dimensional feature space.
- The most common nonlinear choice is the RBF (Gaussian) kernel:
- Here, controls how local each support vector’s influence is.
- Large : very local influence, more complex boundary, higher overfitting risk.
- Small : smoother influence, simpler boundary, higher underfitting risk.
- In practice, tune both and together with cross-validation.
Support Vector Machines In Practice
When to Use SVMs
- When you need a strong baseline for medium-sized datasets.
- When data is high-dimensional and sparse (linear SVM).
- When margin-based robustness is valuable.
- When nonlinear boundaries can be captured with kernels.
When Not to Use SVMs
- When the dataset is extremely large and training time is critical.
- When noise or outliers dominate and is hard to tune.
- When feature scaling is not feasible.
- When you need native probabilistic outputs.
Practical Notes
Preprocessing and Tuning
- Standardise features before training.
- Tune and kernel parameters with cross-validation.
- For RBF SVM, the most important kernel parameter is .
Model Choice
- Prefer linear SVMs for large, sparse feature spaces.
Probability Outputs
- Calibrate probabilities with Platt scaling if required.