Syllabus Map
- Study map: Syllabus Study Map
Introduction
Limitations of Linear Regression
- The standard implementation of linear regression does not guarantee generalisation of the model
- It is limited to the calculation of empirical Error (MSE) without:
- Controlling the norm of the weight vector
- Regularisation of the model
- This leads to poorer performance of the model for limited viable practical applications
Use of Regularisation
- In order to mitigate these limitations, regularisation can be used to control the model
- Regularisation adds an additional term to the Error, which is minimised
- This leads to a new minimisation objective - the Regularised Loss Minimisation (RLM) - which outputs a hypothesis where:
- Where:
- is the weight vector,
- is the empirical loss,
- is the regularised loss from the regularisation function.
Stability
- A learning algorithm is stable if a small change in the input training set does not change the output hypothesis by much.
Uniform Stability
-
A formal way to measure stability is through uniform stability.
-
Let:
- be a learning algorithm
- be the dataset
- be the dataset with the -th sample replaced by some new sample
- and be the hypotheses produced by training on the two datasets
- be the loss of hypothesis on sample
Definition (Uniform Stability)
- Algorithm is -uniformly stable if for all , all , and all samples :
- In words:
- Changing one training example can change the loss by at most .
- A smaller means the algorithm is more stable.
Why Stability Matters
- Stability is directly tied to generalisation.
Generalisation Bound
- If a learning algorithm is -stable, then:
- Meaning:
- Stable algorithms generalise better
- Unstable algorithms overfit by being too sensitive to small perturbations
Why Regularisation Improves Stability
- Without regularisation, the learned weights are:
-
If is nearly singular (e.g., highly collinear features), then:
- A small change in one training point → A large change in → A large change in
-
This is instability.
L1 Regularisation (LASSO)
Overview
- LASSO (Least Absolute Shrinkage and Selection Operator) regression uses a regularisation rule which is defined as
-
Where:
- is a scalar where ,
- is the norm.
-
Applying the learning rule with linear regression and mean-squared Error (MSE) loss:
Features of L1 Regression
Produces Sparse Weights
-
L1 regularisation pushes some weights exactly to zero.
-
This creates a model that selects features automatically.
-
Therefore, L1 regularisation is useful for feature selection, since zero-weight features are effectively removed.
-
In optimisation updates, L1 contributes a constant-magnitude term ( away from zero), which is why it can zero out coefficients.
Leads to Simpler Models
- Unimportant features are removed, meaning that models are more efficient and interpretable.
Gradient Calculation
-
The L1 regulariser is not differentiable at .
-
Therefore, we use the subgradient instead of the gradient.
-
Subgradient of the L1 term:
- Since the L1 norm cannot be differentiated at 0:
- L1 minimisation has no closed-form solution
- It must use iterative algorithms
L2 Regularisation (Ridge Regression)
Overview
- Ridge regression makes use of one of the simplest regularisation rules, which is defined as
-
Where:
- is a scalar where ,
- is the norm.
-
Applying the learning rule with linear regression and mean-squared Error (MSE) loss:
Features of L2 Regression
Improves numerical stability:
- Adding ensures is invertible.
- Prevents the model from blowing up when features are highly correlated.
- L2 regularisation is commonly called weight decay because each update shrinks weights toward zero proportionally to their size.
Reduces model variance:
- Shrinks weights smoothly toward zero.
- Makes the model less sensitive to noise, improving generalisation performance.
Gradient Calculation
- Calculating the gradient of the cost function .
- Where:
- is the regulariser,
- is the MSE loss function.
Gradient of L2 Norm
- The L2 norm is:
- Let . Then:
- Vector form:
Gradient of Ridge Regulariser
- Ridge regression uses the squared L2 norm:
- Its gradient is much simpler:
- Vector form:
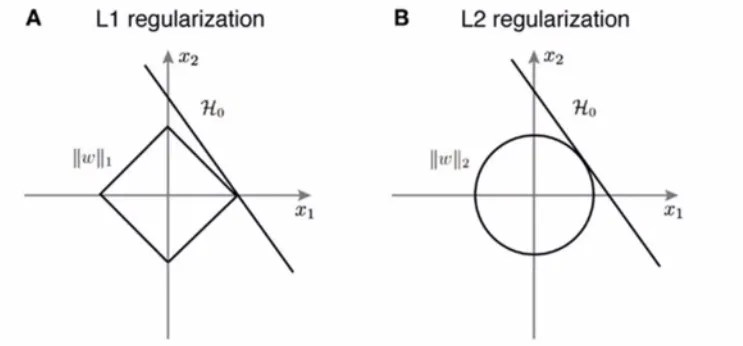
Shape of L1 and L2 Constraints
- Geometrically, regularisation can be viewed as constraining weights to lie inside a norm ball.
- For two parameters :
- L1 constraint () forms a diamond.
- L2 constraint () forms a circle.
- The sharp corners of the L1 diamond make it more likely to hit axes, producing exact zeros (sparsity).
- The smooth L2 circle shrinks weights continuously, usually keeping them non-zero.
L1 and L2 Regularisation In Practice
When to Use L1 and L2 Regularisation
- When you need to reduce overfitting in linear models.
- When features are correlated and coefficients are unstable (L2).
- When you want automatic feature selection and sparsity (L1).
- When training data is limited relative to feature count.
When Not to Use L1 and L2 Regularisation
- When unshrunk coefficients are required for unbiased estimates.
- When features are not standardised and penalties would be uneven.
- When the true relationship is strongly nonlinear.
- When constraints or priors already enforce complexity control.
Practical Notes
Preprocessing
- Standardise all features before applying L1 or L2 penalties.
Model Selection
- Tune via cross-validation, not by training loss.
- Use Elastic Net when you want sparsity with grouped features.
Interpretation
- Track coefficient paths to understand shrinkage effects.