Syllabus Map
- Study map: Syllabus Study Map
Overview
- Clustering groups data by similarity without labels.
- Different methods make different assumptions about cluster shape.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
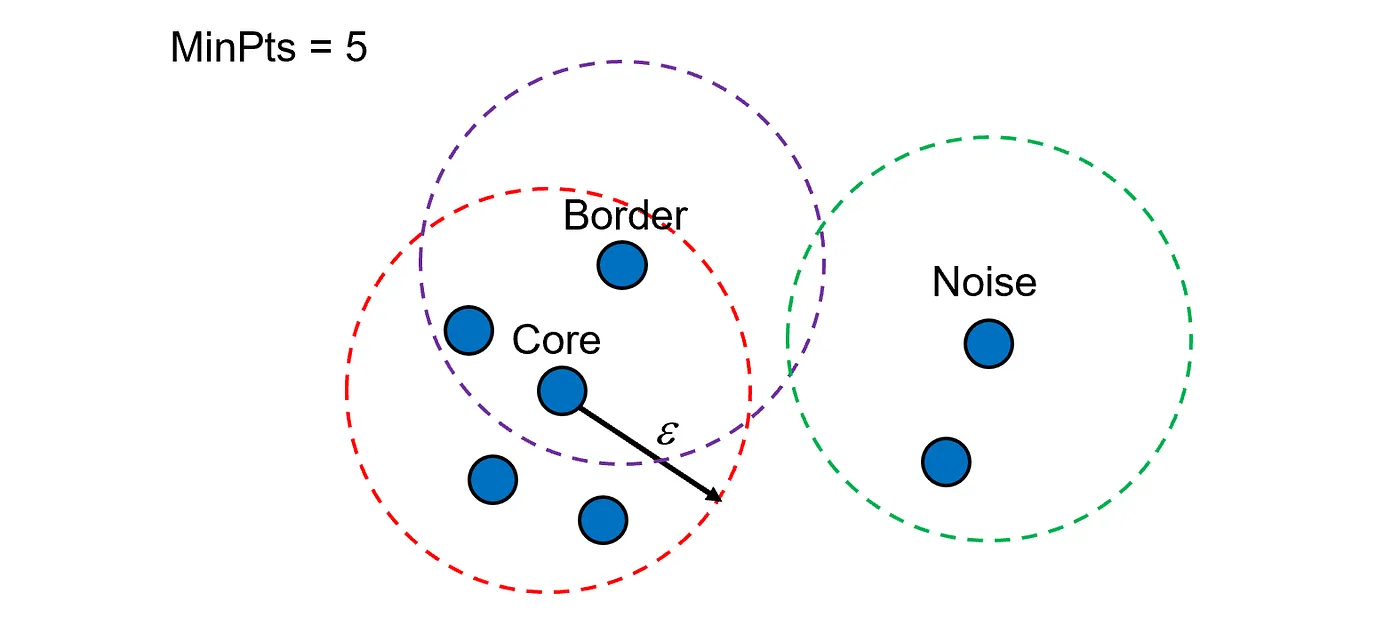
Core Idea
- Groups points by density rather than distance alone.
- Finds clusters of arbitrary shape.
- Classifies points as:
- Core points: have at least
min_samplespoints within radiuseps. - Border points: are close to a core point but are not themselves core.
- Noise points: are not density-reachable from any core point.
- Core points: have at least
How It Works (Step-by-Step)
Step 1: Define Neighborhood and Density Threshold
- Choose
epsandmin_samples. - For each point , define its -neighborhood:
Step 2: Identify Core Points
- A point is a core point if:
- Points that are not core may later become border or noise points.
Step 3: Expand Clusters from Core Points
- Start from an unvisited core point and create a new cluster.
- Add all points that are density-reachable from it (directly or through a chain of core points).
Step 4: Attach Border Points
- A border point is not core itself but lies in the -neighborhood of a core point.
- Border points are assigned to nearby expanded clusters.
Step 5: Label Remaining Points as Noise
- Any point not assigned to a cluster is marked as noise (often label
-1).
Key Hyperparameters
eps: neighborhood size. Too small can split clusters; too large can merge clusters.min_samples: minimum local density. Higher values make the method more conservative.metric: distance function (e.g.,euclidean,manhattan,cosine).
Practical Notes
Handles outliers well.
- Points that do not belong to dense regions are labeled as noise instead of being forced into a cluster.
Struggles with varying densities.
- A single global
epsmay not fit both sparse and dense regions in the same dataset.
Scale features before DBSCAN.
- DBSCAN is distance-based, so unscaled features can dominate neighborhood formation.
Hierarchical Clustering
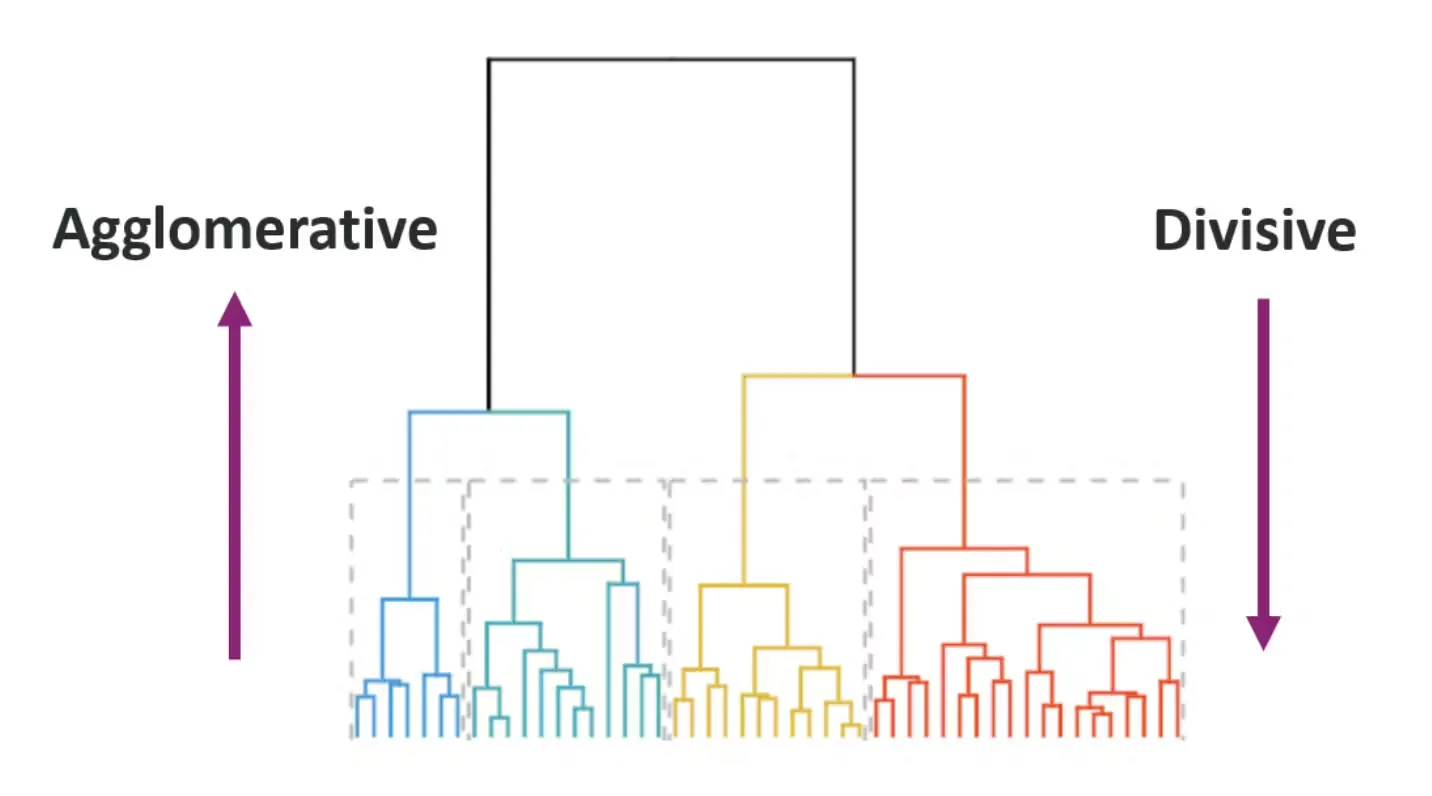
Core Idea
- Builds a tree of clusters (dendrogram).
- Can be agglomerative (bottom-up) or divisive (top-down).
How It Works (Step-by-Step)
Agglomerative Clustering (Bottom-Up)
Step 1: Compute Pairwise Distances
- Build the distance matrix between data points:
Step 2: Initialise Singleton Clusters
- Start with one cluster per point:
Step 3: Measure Inter-Cluster Distance with a Linkage Rule
- Linkage is the rule used to define the distance between two clusters and from point-level distances.
- It determines which pair of clusters is considered “closest” and therefore merged next.
- At each iteration, compute cluster distance using a chosen linkage (examples):
- Single linkage:
- Complete linkage:
- Average linkage:
Step 4: Merge Closest Clusters Iteratively
- Merge the pair with minimum linkage distance.
- Repeat until one cluster remains, recording merges to form a dendrogram.
Step 5: Cut the Dendrogram
- Choose a cut height (or target number of clusters ).
- Clusters below that cut become the final partition.
Divisive Clustering (Top-Down)
Step 1: Start with One Cluster
- Place all points in a single cluster:
Step 2: Select a Cluster to Split
- Pick the cluster with highest heterogeneity (e.g., largest diameter or variance).
- The goal is to split the least coherent cluster first.
Step 3: Split the Selected Cluster
- Partition that cluster into two child clusters (often using a 2-way method such as k-means with ).
- Choose the split that best improves within-cluster compactness and between-cluster separation.
Step 4: Repeat Recursive Splitting
- Continue splitting clusters until a stopping rule is met.
- Common stopping rules: target number of clusters, minimum cluster size, or low within-cluster variance.
Step 5: Read Final Clusters from the Dendrogram
- The hierarchy can be cut at different levels to produce coarse or fine groupings.
Linkage Criteria
- Single linkage: minimum pairwise distance between clusters.
- Complete linkage: maximum pairwise distance between clusters.
- Average linkage: average pairwise distance between clusters.
- Ward linkage: merges that minimally increase within-cluster variance.
Practical Notes
No need to pre-specify number of clusters.
- You can inspect the dendrogram first, then decide where to cut based on separation.
Can be expensive for large datasets.
- Computing and storing pairwise distances can become costly in time and memory.
Choice of linkage changes cluster shape.
- Different linkage rules can produce very different dendrograms on the same data.
Spectral Clustering
Core Idea
- Uses eigenvectors of a graph Laplacian.
- Finds clusters in a transformed space.
How It Works (Step-by-Step)
Step 1: Build an Affinity (Similarity) Matrix
- Define similarity between points, for example with RBF kernel:
- Alternatively, use a k-NN graph to keep only local edges.
Step 2: Compute Degree Matrix and Graph Laplacian
- Degree matrix:
- Unnormalised Laplacian:
- Common normalised variant:
Step 3: Solve Eigenproblem
- Compute the first
keigenvectors of the chosen Laplacian. - Form embedding matrix using these eigenvectors.
Step 4: Embed Points in Spectral Space
- Represent each original point by its row in .
- Nearby points in graph connectivity become closer in this transformed space.
Step 5: Cluster in the Embedded Space
- Run k-means on rows of to produce final cluster labels.
Why It Helps
- The spectral embedding separates points by graph connectivity.
- This allows better recovery of non-convex clusters where plain k-means fails.
Practical Notes
Good for non-convex clusters.
- Works well when clusters are connected components in a similarity graph rather than spherical blobs.
Requires choosing number of clusters.
- You still need
k(often selected via eigengap heuristics or validation).
Sensitive to graph construction.
- Results depend on affinity choice (
rbf,nearest_neighbors) and graph hyperparameters.